
Findings of ACL 2026
Towards Bridging the Reward-Generation Gap in Direct Alignment Algorithms
Problem
Direct alignment methods score full responses, but language models actually commit to prefixes first during decoding.
Intervention
POET compares preferred and dispreferred responses at matched length, shifting attention toward the part of the sequence that drives generation.
Benefit
The method is simple, hyperparameter-free in its default form, and improves alignment quality across several settings.

Motivation
Direct alignment algorithms such as DPO and SimPO are popular because they simplify the RLHF pipeline. Instead of learning a separate reward model and then optimizing with reinforcement learning, they train directly from preference pairs. That simplicity is a major reason these methods are so widely used.
But there is an underappreciated mismatch hiding inside that setup. Training rewards are defined over complete responses, whereas inference unfolds one token at a time from left to right. A model can therefore become better at ranking full sequences under the training objective without becoming equally better at generating the crucial early tokens that steer the rest of the response.
We call this the reward-generation gap. The paper asks a straightforward question: can we reduce that gap without redesigning direct alignment from scratch?
Why Prefixes Matter
Autoregressive generation is path-dependent. Once a model makes a weak choice near the beginning of a response, later tokens are produced under that weaker context. Early mistakes can compound. In practice, prefix tokens often determine the direction, tone, structure, and safety profile of the whole answer.
That is why sequence-level optimization can miss something important. It treats the response as a single object, but the model experiences generation as a sequence of irreversible local commitments. If the preference signal is dominated by later suffix differences, learning may underweight the part of the response that matters most during actual decoding.
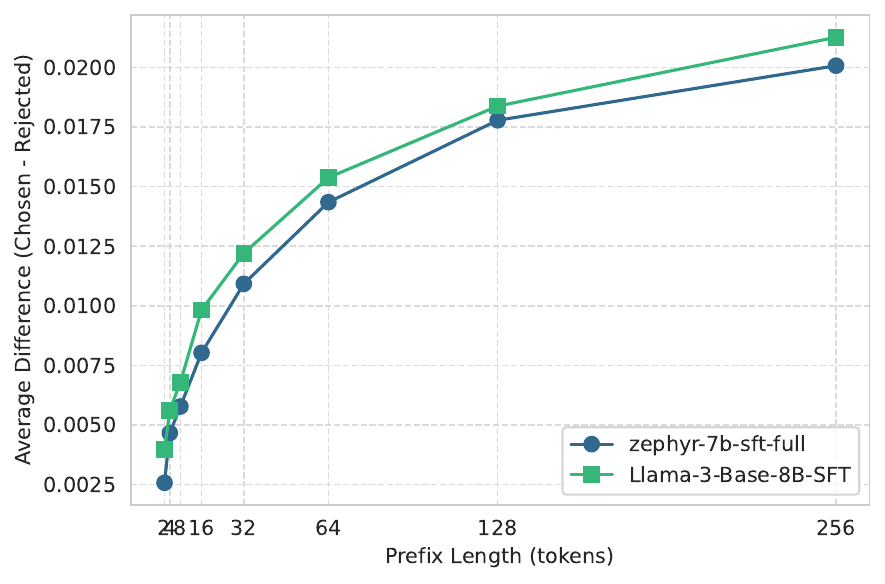
Early signal. The quality gap between preferred and dispreferred responses already emerges early in the prefix and then tends to saturate, which makes prefix-aware comparisons especially natural.
POET in One Idea
POET, short for Prefix-Oriented Equal-length Training, is intentionally simple. For each preferred and dispreferred pair, we truncate both responses to the length of the shorter one and train the underlying direct alignment algorithm on those matched-length responses.
The intervention is small, but the intuition is strong. Equal-length comparison prevents later suffixes from dominating the signal and encourages the method to focus on matched prefixes. That makes the learning problem better aligned with how the model will later generate text.
Universal
POET works on top of DPO, SimPO, and other direct alignment pipelines because it modifies the training pairs rather than the objective itself.
Lightweight
No extra reward model, no custom decoding trick, and no mandatory new hyperparameter in the default setup.
Targeted
The method addresses a specific mismatch between training and inference instead of adding general complexity.
Why Equal-Length Training Helps
The natural concern is whether truncation might corrupt the preference label. If the preferred response becomes clearly better only near the end, matching lengths could discard the decisive evidence. Our analysis suggests that many preference datasets do not behave that way. The quality gap often appears early and then grows with diminishing returns.
That means equal-length training can remove an important bias without throwing away most of the useful signal. Later tokens still matter, but they are not always the most informative part of the comparison for learning to generate better answers.
From that perspective, POET is not a heuristic bolt-on. It is a data-level way to bring the training comparison closer to the structure of generation.
Results Across Settings
The empirical pattern is consistent: POET improves alignment quality across multiple model families and multiple direct alignment objectives, while keeping the implementation burden extremely low.
| Setting | Baseline | + POET | Gain |
|---|---|---|---|
| Mistral-Base (7B) + DPO, AlpacaEval 2 LC | 12.9 | 24.7 | +11.8 |
| Llama-3-Base (8B) + DPO, AlpacaEval 2 LC | 16.9 | 28.4 | +11.5 |
| Llama-3-Base (8B) + SimPO, AlpacaEval 2 LC | 28.0 | 33.8 | +5.8 |
| Mistral-Base (7B) + DPO, safety rate | 45.2 | 82.1 | +36.9 |
Representative results reported in the paper. The strongest gains appear in exactly the settings where getting the early trajectory of a response right matters most.
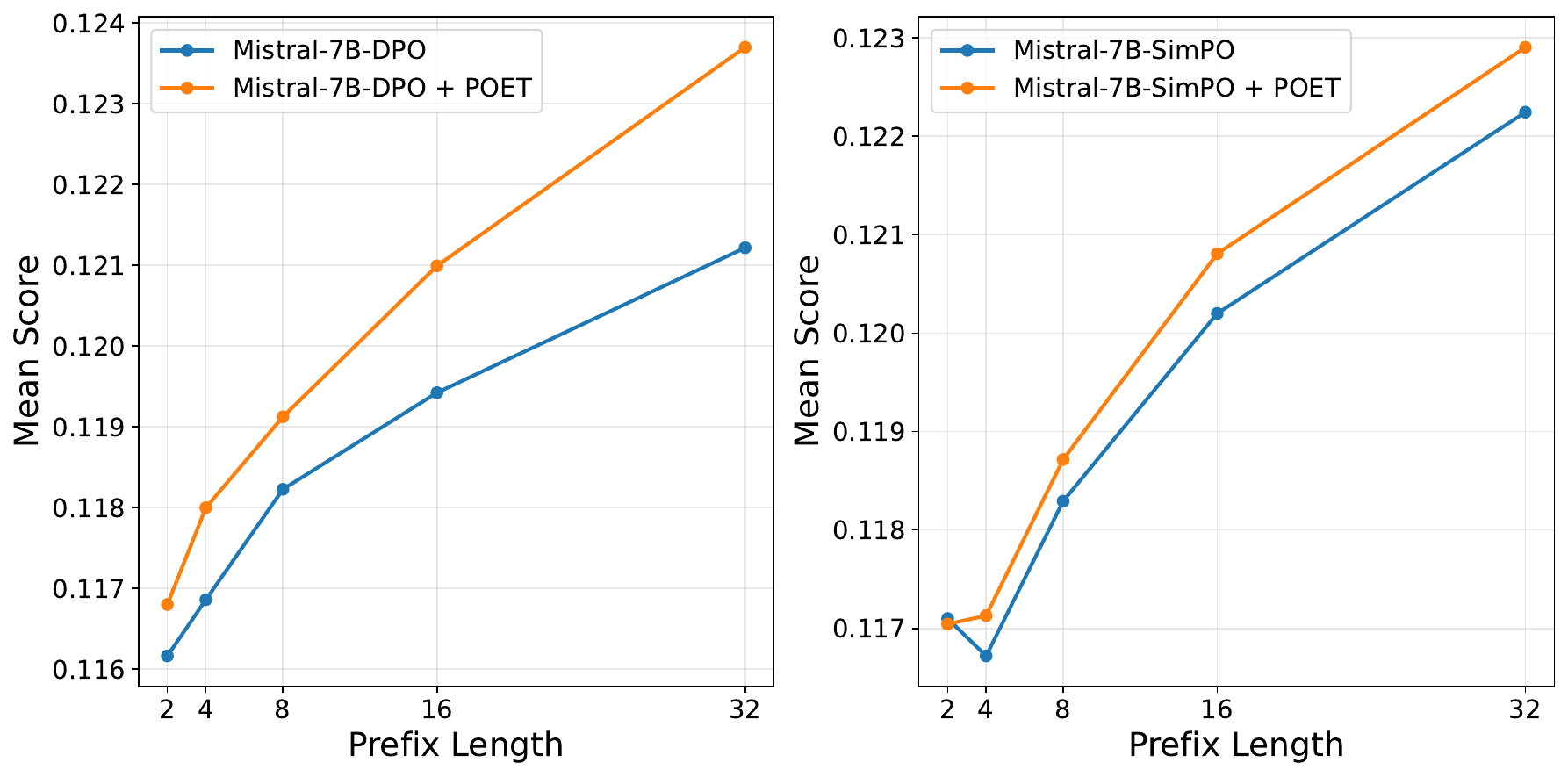
Mechanism validation. Models trained with POET generate stronger prefixes across prefix lengths, which directly supports the paper's core explanation of why the method works.
More context: when POET is likely to help
POET is most compelling when preferred and dispreferred responses already diverge meaningfully in their early prefixes, and when the task depends heavily on getting the beginning of the answer right. That makes the method especially natural for instruction following and safety alignment.
By contrast, if a dataset's preference labels depend mostly on very late tokens, equal-length truncation may help less. The method is therefore best understood as a targeted correction for a specific training-inference mismatch, not as a claim that every preference dataset should always be truncated.
Takeaway
The broader lesson of this paper is that alignment objectives should respect generation dynamics. Direct alignment methods are appealing because they are simple, but sequence-level simplicity can hide a real mismatch with how language models actually decode.
POET shows that a very small intervention can reduce that mismatch. By forcing preferred and dispreferred responses to be compared at the same length, the training signal becomes more sensitive to prefixes and therefore more faithful to the part of the sequence that dominates real generation. That combination of clarity, simplicity, and broad empirical gain is what makes the result exciting to us.
Citation
@inproceedings{xiao2026poet,
title={Towards Bridging the Reward-Generation Gap in Direct Alignment Algorithms},
author={Xiao, Zeguan and Chen, Yun and Yang, Jian and Chen, Guanhua and Tang, Ke},
booktitle={Findings of the Association for Computational Linguistics: ACL 2026},
year={2026}
}