
ACL 2026
Modeling LLM Unlearning as an Asymmetric Two-Task Learning Problem
Retention
Treat general capability as the primary objective instead of a side constraint that can be traded away too aggressively.
Forgetting
Inject forgetting only in directions that do not actively conflict with the retain signal.
Guarantee
SAGO builds updates that stay aligned with retention coordinate by coordinate, not just on average.
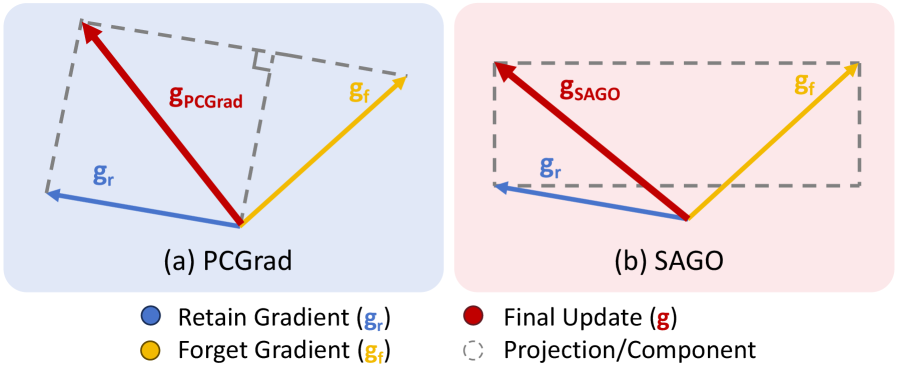
Motivation
LLM unlearning is attractive because it aims to remove dangerous or private knowledge from a model itself, rather than only teaching the model to refuse when asked. In principle that is a stronger defense: if a model genuinely no longer retains a harmful capability, jailbreaks should become much less effective.
The hard part is that unlearning is never just a forgetting problem. It is also a retention problem. Push too hard and the model loses useful knowledge and general performance. Push too softly and the target knowledge remains recoverable. This is why many unlearning methods end up living on an uncomfortable frontier between forgetting strength and capability preservation.
Our paper argues that the usual framing is slightly off. The problem is not simply “balance two losses better.” The real question is how to combine updates so that forgetting is allowed only where it does not sabotage retention.
Asymmetric Two-Task Learning
We recast LLM unlearning as an asymmetric two-task learning problem. There are two tasks in play, but they do not have equal status:
Primary task
Retention should be preserved whenever possible because it represents the model's general capability and non-target knowledge.
Auxiliary task
Forgetting is still necessary, but it should operate under a do-no-harm principle relative to retention.
Design shift
This changes the engineering target from loss balancing to retention-prioritized gradient synthesis.
That asymmetric framing is important because it matches how practitioners already evaluate unlearning methods. A method is not considered successful if it forgets well but destroys the model. We should therefore encode that hierarchy directly into the update rule.
How SAGO Synthesizes Gradients
At each update step, we compute two signals: a forget gradient and a retain gradient. The question is how to merge them. A naive difference-style update can work against retention in exactly the coordinates where general capability is stored. PCGrad improves on this by removing part of the conflict, but it still reasons at a coarser level.
SAGO, short for Sign-Align Gradient Optimization, goes finer-grained. It examines the relationship between forget and retain gradients element by element:
- If a coordinate is conflicting, SAGO keeps the retain direction and blocks the forget direction there.
- If a coordinate is aligned, SAGO allows the forget update through because it does not fight retention.
- The final update therefore never points against the retain signal in any coordinate.
The result is a simple rule with a strong intuition: keep the parts of forgetting that are safe, and suppress the parts that would damage what we want to preserve.
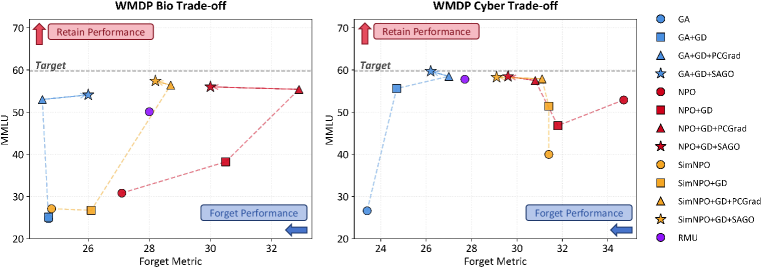
What the Results Show
Across WMDP and RWKU, SAGO consistently improves the trade-off curve instead of merely moving to a different operating point. That is the main empirical message of the paper.
| Method | MMLU (↑) | Forget Acc (↓) | Target Recovery |
|---|---|---|---|
| Naive | 26.7 | 26.1 | 44.6% |
| + PCGrad | 56.4 | 28.9 | 94.0% |
| + SAGO | 57.4 | 28.2 | 96.0% |
Representative result on WMDP Bio with SimNPO+GD. SAGO recovers more of the original model's general performance while maintaining comparable forgetting strength.
The broader pattern is just as encouraging. On RWKU, SAGO preserves neighboring knowledge much better than stronger but less selective baselines. That matters because practical unlearning is rarely about erasing one isolated fact. It is about removing a target while keeping the surrounding knowledge graph intact.
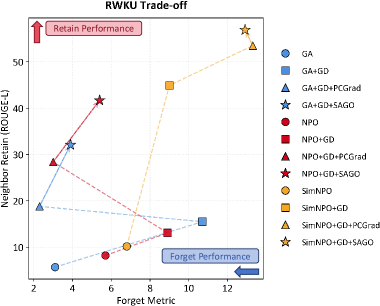
RWKU trade-offs. SAGO also improves the frontier on real-world knowledge unlearning, not only on the safety-oriented WMDP setting.
More evidence: optimization dynamics and geometry
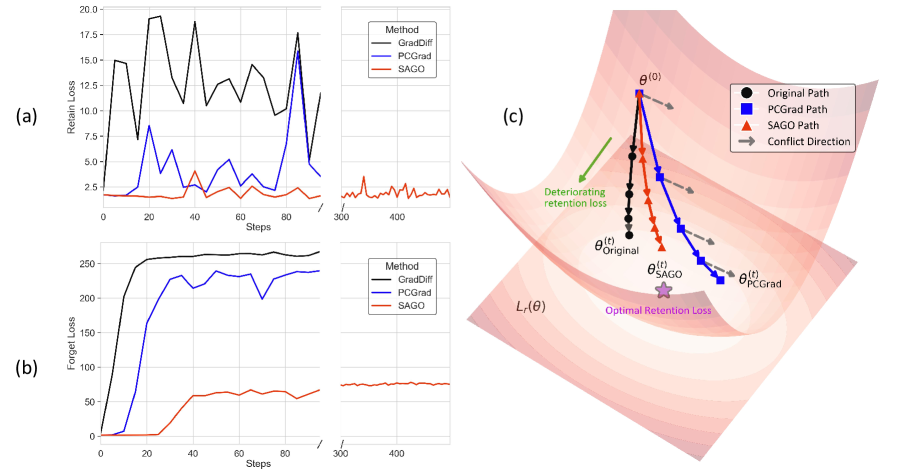
Loss dynamics. SAGO keeps retain loss under tighter control while still driving the forget objective effectively.
| Method | Forget-Retain | Comb-Retain | Comb-Forget |
|---|---|---|---|
| GradDiff | -0.22 | 0.55 | 0.82 |
| PCGrad | -0.22 | 0.76 | 0.52 |
| SAGO | -0.15 | 0.87 | 0.48 |
Geometry analysis. SAGO yields the strongest alignment with the retain direction while keeping enough forgetting pressure to remain effective.
Why the Geometry Matters
One reason we like SAGO is that it is not just an empirical trick. Its behavior lines up with the core failure mode of unlearning. When forget and retain gradients disagree, the model is being asked to modify parameters that likely support general capability. Those are exactly the places where a careless update causes collateral damage.
SAGO addresses this directly. Instead of averaging away the conflict, it respects the hierarchy between tasks. That gives it a more faithful objective: forgetting should happen, but only where it is compatible with retention. In that sense, the method is both practical and conceptually clean.
Takeaway
The paper's main message is simple: LLM unlearning should be treated as an asymmetric optimization problem. Once we encode that asymmetry into gradient synthesis, the forgetting-retention trade-off becomes much easier to navigate.
SAGO is appealing because it stays lightweight. It can be plugged into existing forget-plus-retain pipelines, introduces a clear safety-first inductive bias, and consistently pushes the Pareto frontier in the right direction. For practitioners, that means better retention at comparable forgetting strength. For researchers, it suggests that update geometry is at least as important as loss design in unlearning.
Citation
@inproceedings{xiao2026sago,
title={Modeling LLM Unlearning as an Asymmetric Two-Task Learning Problem},
author={Xiao, Zeguan and Li, Siqing and Wang, Yong and Wei, Xuetao and Yang, Jian and Chen, Yun and Chen, Guanhua},
booktitle={Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL)},
year={2026}
}